Structure from Motion (SfM)¶
Theia has a full Structure-from-Motion pipeline that is extremely efficient. Our
overall pipeline consists of several steps. First, we extract features (SIFT is
the default). Then, we perform two-view matching and geometric verification to
obtain relative poses between image pairs and create a ViewGraph. Next,
we perform either incremental or global SfM.
- Extract features in images.
- Match features to obtain image correspondences.
- Estimate camera poses from two-view matches and geometries using incremental or global SfM.
Incremental SfM is the standard approach that adds on one image at a time to
grow the reconstruction. While this method is robust, it is not scalable because
it requires repeated operations of expensive bundle adjustment. Global SfM is
different from incremental SfM in that it considers the entire view graph at the
same time instead of incrementally adding more and more images to the
Reconstruction. Global SfM methods have been proven to be very fast
with comparable or better accuracy to incremental SfM approaches (See
[JiangICCV], [MoulonICCV], [WilsonECCV2014]), and they are much more readily
parallelized. After we have obtained camera poses, we perform triangulation and
BundleAdjustment to obtain a valid 3D reconstruction consisting of
cameras and 3D points.
First, we will describe the fundamental classes of our SfM pipeline:
View, the main class encapsulating an image, its pose, and which features it observesCamera, a member of theViewclass containing pose informationTrack, a 3D point and information about which cameras observe itReconstruction, the core SfM class containing a set ofViewandTrackobjectViewGraphcontaining matching information and relative pose information betweenViewobjectsTwoViewInfo, containing relative pose information between two views.
Then, we will describe the various SfM pipelines in Theia.
Core Classes and Data Structures¶
Views and Tracks¶
-
class
View¶
At the heart of our SfM framework is the View class which represents
everything about an image that we want to reconstruct. It contains information
about features from the image, camera pose information, and EXIF
information. Views make up our basic visibility constraints and are a fundamental
part of the SfM pipeline.
-
class
Track¶
A Track represents a feature that has been matched over potentially
many images. When a feature appears in multiple images it typically means that
the features correspond to the same 3D point. These 3D points are useful
constraints in SfM reconstruction, as they represent the “structure” in
“Structure-from-Motion” and help to build a point cloud for our reconstruction.
Reconstruction¶
-
class
Reconstruction¶

At the core of our SfM pipeline is an SfM Reconstruction. A
Reconstruction is the representation of a 3D reconstruction consisting
of a set of unique Views and Tracks. More importantly, the
Reconstruction class contains visibility information relating all of
the Views and Tracks to each other. We identify each View uniquely
based on the name (a string). A good name for the view is the filename of the
image that corresponds to the View
When creating an SfM reconstruction, you should add each View and
Track through the Reconstruction object. This will ensure that
visibility information (such as which Tracks are observed a given View and which
Views see a given Track) stays accurate. Views and Tracks are given a unique ID
when added to the Reconstruction to help make use of these structures
lightweight and efficient.
-
ViewId
Reconstruction::AddView(const std::string &view_name)¶ Adds a view to the reconstruction with the default initialization. The ViewId returned is guaranteed to be unique or will be kInvalidViewId if the method fails. Each view is uniquely identified by the view name (a good view name could be the filename of the image).
-
ViewId
Reconstruction::AddView(const std::string &view_name, const CameraIntrinsicsGroupId group_id)¶ Same as above, but explicitly sets the CameraIntrinsicsGroupId. This is useful for when multiple cameras share the same intrinsics.
-
bool
Reconstruction::RemoveView(const ViewId view_id)¶ Removes the view from the reconstruction and removes all references to the view in the tracks.
Note
Any tracks that have length 0 after the view is removed will also be removed.
-
CameraIntrinsicsGroupId
Reconstruction::CameraIntrinsicsGroupIdFromViewId(const ViewId view_id) const¶ Returns the camera intrinsics group id for the given view.
-
std::unordered_set<ViewId>
Reconstruction::GetViewsInCameraIntrinsicsGroup(const CameraIntrinsicsGroupId group_id) const¶ Returns all view_ids with the given camera intrinsics group id. If an invalid or non-existant group is chosen then an empty set will be returned.
-
std::unordered_set<CameraIntrinsicsGroupId>
CameraIntrinsicsGroupIds() const¶ Returns all camera intrinsics group ids present in the reconstruction.
-
int
Reconstruction::NumViews() const¶
-
int
Reconstruction::NumTracks() const¶
-
View *
Reconstruction::MutableView(const ViewId view_id)¶ Returns the View or a nullptr if the track does not exist.
-
std::vector<ViewId>
Reconstruction::ViewIds() const¶ Return all ViewIds in the reconstruction.
-
ViewId
Reconstruction::ViewIdFromName(const std::string &view_name) const¶ Returns to ViewId of the view name, or kInvalidViewId if the view does not exist.
-
TrackId
Reconstruction::AddTrack(const std::vector<std::pair<ViewId, Feature>> &track)¶ Add a track to the reconstruction with all of its features across views that observe this track. Each pair contains a feature and the corresponding ViewId that observes the feature. A new View will be created if a View with the view name does not already exist. This method will not estimate the position of the track. The TrackId returned will be unique or will be kInvalidTrackId if the method fails.
-
bool
Reconstruction::RemoveTrack(const TrackId track_id)¶ Removes the track from the reconstruction and from any Views that observe this track. Returns true on success and false on failure (e.g., the track does not exist).
-
Track *
Reconstruction::MutableTrack(const TrackId track_id)¶ Returns the Track or a nullptr if the track does not exist.
-
std::vector<TrackId>
Reconstruction::TrackIds() const¶ Return all TrackIds in the reconstruction.
ViewGraph¶
-
class
ViewGraph¶
A ViewGraph is a basic SfM construct that is created from two-view
matching information. Any pair of views that have a view correlation form an
edge in the ViewGraph such that the nodes in the graph are
View that are connected by TwoViewInfo objects that contain
information about the relative pose between the Views as well as matching
information.
Once you have a set of views and match information, you can add them to the view graph:
std::vector<View> views;
// Match all views in the set.
std::vector<ViewIdPair, TwoViewInfo> view_pair_matches;
ViewGraph view_graph;
for (const auto& view_pair : view_pair_matches) {
const ViewIdPair& view_id_pair = view_pair.first;
const TwoViewInfo& two_view_info = view_pair.second;
// Only add view pairs to the view graph if they have strong visual coherence.
if (two_view_info.num_matched_features > min_num_matched_features) {
view_graph.AddEdge(views[view_id_pair.first],
views[view_id_pair.second],
two_view_info);
}
}
// Process and/or manipulate the view graph.
The edge values are especially useful for one-shot SfM where the relative poses
are heavily exploited for computing the final poses. Without a proper
ViewGraph, one-shot SfM would not be possible.
TwoViewInfo¶
-
class
TwoViewInfo¶
After image matching is performed we can create a ViewGraph that
explains the relative pose information between two images that have been
matched. The TwoViewInfo struct is specified as:
struct TwoViewInfo {
double focal_length_1;
double focal_length_2;
Eigen::Vector3d position_2;
Eigen::Vector3d rotation_2;
// Number of features that were matched and geometrically verified betwen the
// images.
int num_verified_matches;
};
This information serves the purpose of an edge in the view graph that describes visibility information between all views. The relative poses here are used to estimate global poses for the cameras.
Building a Reconstruction¶
Theia implements a generic interface for estimating a Reconstruction
with the ReconstructionEstimator. This class takes in as input a
ViewGraph with connectivity and relative pose information, and a
Reconstruction with view and track information and unestimated poses
and 3d points. All SfM pipelines are derived directly from the
ReconstructionEstimator class. This allows for a consistent interface
and also the ability to choose the reconstruction pipeline at run-time.
However, the most common use case for SfM pipelines is to input images and
output SfM reconstructions. As such, Theia implements a
ReconstructionBuilder utility class. The high-level responsibilities of
these classes are:
ReconstructionBuildertakes as input either images or a set of pre-computed matches (computed with Theia or any other technique). If images are passed in, users may choose the type of feature, feature matching strategy, and more. After matches are computed, theReconstructionBuildercan call aReconstructionEstimatorto compute an SfM ReconstructionReconstructionEstimatoris the abstract interface for classes that estimate SfM reconstructions. Derived classes implement techniques such as incremental SfM or global SfM, and may be easily extended for new type of SfM pipelines. This class is called by theReconstructionBuilder(see below) to estimate an SfM reconstruction from images and/or feature matches.
-
class
ReconstructionBuilder¶
-
ReconstructionBuilder::ReconstructionBuilder(const ReconstructionBuilderOptions &options)¶
-
bool
ReconstructionBuilder::AddImage(const std::string &image_filepath)¶ Add an image to the reconstruction.
-
bool
ReconstructionBuilder::AddImage(const std::string &image_filepath, const CameraIntrinsicsGroupId camera_intrinsics_group)¶ Same as above, but with the camera intrinsics group specified.
-
bool
ReconstructionBuilder::AddImageWithCameraIntrinsicsPrior(const std::string &image_filepath, const CameraIntrinsicsPrior &camera_intrinsics_prior)¶ Same as above, but with the camera priors manually specified. This is useful when calibration or EXIF information is known ahead of time. Note, if the CameraIntrinsicsPrior is not explicitly set, Theia will attempt to extract EXIF information for camera intrinsics.
-
bool
ReconstructionBuilder::AddImageWithCameraIntrinsicsPrior(const std::string &image_filepath, const CameraIntrinsicsPrior &camera_intrinsics_prior, const CameraIntrinsicsGroupId camera_intrinsics_group_id)¶
-
bool
ReconstructionBuilder::AddTwoViewMatch(const std::string &image1, const std::string &image2, const ImagePairMatch &matches)¶ Add a match to the view graph. Either this method is repeatedly called or ExtractAndMatchFeatures must be called. You may obtain a vector of ImagePairMatch from a Theia match file or from another custom form of matching.
-
bool
ReconstructionBuilder::ExtractAndMatchFeatures()¶ Extracts features and performs matching with geometric verification. Images must have been previously added with the
AddImageorAddImageWithCameraIntrinsicsPrior.
-
void
ReconstructionBuilder::InitializeReconstructionAndViewGraph(Reconstruction *reconstruction, ViewGraph *view_graph)¶ Initializes the reconstruction and view graph explicitly. This method should be used as an alternative to the Add* methods.
Note
The ReconstructionBuilder takes ownership of the reconstruction and view graph.
-
bool
ReconstructionBuilder::BuildReconstruction(std::vector<Reconstruction *> *reconstructions)¶ Estimates a Structure-from-Motion reconstruction using the specified ReconstructionEstimator that was set in the
reconstruction_estimator_optionsfield (see below). Once a reconstruction has been estimated, all views that have been successfully estimated are added to the output vector and we estimate a reconstruction from the remaining unestimated views. We repeat this process until no more views can be successfully estimated, so eachReconstructionobject in the output vector is an independent reconstruction of the scene.
Setting the ReconstructionBuilder Options¶
-
class
ReconstructionBuilderOptions¶
The ReconstructionBuilder has many customizable options that can easily
be set to modify the functionality, strategies, and performance of the SfM
reconstruction process. This includes options for feature description
extraction, feature matching, which SfM pipeline to use, and more.
-
std::shared_ptr<RandomNumberGenerator>
rng¶ If specified, the reconstruction process will use the user-supplied random number generator. This allows users to provide a random number generator with a known seed so that the reconstruction process may be deterministic. If rng is not supplied, then the seed is initialized based on the time.
-
int
ReconstructionBuilderOptions::num_threads¶ DEFAULT:
1Number of threads used. Each stage of the pipeline (feature extraction, matching, estimation, etc.) will use this number of threads.
-
bool
ReconstructionBuilderOptions::reconstruct_largest_connected_component¶ DEFAULT:
falseBy default, the ReconstructionBuilder will attempt to reconstruct as many models as possible from the input data. If set to true, only the largest connected component is reconstructed.
-
bool
ReconstructionBuilderOptions::only_calibrated_views¶ DEFAULT:
falseSet to true to only accept calibrated views (from EXIF or elsewhere) as valid inputs to the reconstruction process. When uncalibrated views are added to the reconstruction builder they are ignored with a LOG warning.
-
int
ReconstructionBuilderOptions::min_track_length¶ DEFAULT:
2Minimum allowable track length. Short tracks are often less stable during triangulation and bundle adjustment and so they may be filtered for stability.
-
int
ReconstructionBuilderOptions::max_track_length¶ DEFAULT:
20Maximum allowable track length. Tracks that are too long are exceedingly likely to contain outliers. Any tracks that are longer than this will be split into multiple tracks.
-
int
ReconstructionBuilderOptions::min_num_inlier_matches¶ DEFAULT:
30Minimum number of geometrically verified inliers that a view pair must have in order to be considered a good match.
-
DescriptorExtractorType
ReconstructionBuilderOptions::descriptor_type¶ DEFAULT:
DescriptorExtractorType::SIFTDescriptor type for extracting features. See //theia/image/descriptor/create_descriptor_extractor.h
-
FeatureDensity
ReconstructionBuilderOptions::feature_density¶ DEFAULT:
FeatureDensity::NORMALThe density of the feature extraction. This may be set to
SPARSE,NORMAL, orDENSE
-
MatchingStrategy
ReconstructionBuilderOptions::matching_strategy¶ DEFAULT:
MatchingStrategy::BRUTE_FORCEMatching strategy type. Current the options are
BRUTE_FORCEorCASCADE_HASHINGSee //theia/matching/create_feature_matcher.h
-
FeatureMatcherOptions
ReconstructionBuilderOptions::matching_options¶ Options for computing matches between images. See
FeatureMatcherOptionsfor more details.
-
VerifyTwoViewMatchesOptions
ReconstructionBuilderOptions::geometric_verification_options¶ Settings for estimating the relative pose between two images to perform geometric verification. See //theia/sfm/verify_two_view_matches.h
-
ReconstructionEstimatorOptions
ReconstructionBuilderOptions::reconstruction_estimator_options¶ Setting for the SfM estimation. The full list of
ReconstructionEstimatorOptionsmay be found below.
-
std::string
ReconstructionBuilderOptions::output_matches_file¶ If you want the matches to be saved, set this variable to the filename that you want the matches to be written to. Image names, inlier matches, and view metadata so that the view graph and tracks may be exactly recreated.
The Reconstruction Estimator¶
-
class
ReconstructionEstimator¶
This is the base class for which all SfM reconstruction pipelines derive
from. Whereas the ReconstructionBuilder focuses on providing an
end-to-end interface for SfM, the ReconstructionEstimator focuses
solely on the SfM estimation. That is, it takes a viewing graph with matching
and visibility information as input and outputs a fully estimated 3D model.
The ReconstructionEstimator is an abstract interface, and each of the
various SfM pipelines derive directly from this class. This allows us to easily
implement e.g., incremental or global SfM pipelines with a clean, consistent
interface while also allowing polymorphism so that type of SfM pipeline desired
may easily be chosen at run-time.
-
ReconstructionEstimator::ReconstructionEstimator(const ReconstructorEstimatorOptions &options)¶
-
ReconstructionEstimatorSummary
ReconstructionEstimator::Estimate(const ViewGraph &view_graph, Reconstruction *reconstruction)¶ Estimates the cameras poses and 3D points from a view graph. The derived classes must implement this method to estimate a 3D reconstruction.
-
static ReconstructionEstimator *
ReconstructionEstimator::Create(const ReconstructionEstimatorOptions &options)¶ Creates a derived
ReconstructionEstimatorclass from the options passed in. For instance, anIncrementalReconstructionEstimatorwill be returned if incremental SfM is desired.
Setting Reconstruction Estimator Options¶
-
class
ReconstructorEstimatorOptions¶
There are many, many parameters and options to choose from and tune while
performing SfM. All of the available parameters may be set as part of the
ReconstructionEstimatorOptions that are required in the
ReconstructionEstimator constructor. The documentation here attempts to
provide the high-level summary of these options; however, you should look at the
header //theia/sfm/reconstruction_estimator_options.h file for a fully detailed
description of these options.
-
ReconstructionEstimatorType
ReconstructorEstimatorOptions::reconstruction_estimator_type¶ DEFAULT:
ReconstructionEstimatorType::GLOBALType of reconstruction estimation to use. Options are
ReconstructionEstimatorType::GLOBALorReconstructionEstimatorType::INCREMENTAL. Incremental SfM is the standard sequential SfM (see below) that adds on one image at a time to gradually grow the reconstruction. This method is robust but not scalable. Global SfM, on the other hand, is very scalable but is considered to be not as robust as incremental SfM. This is not a limitation of the Theia implementations, but a currently fundamental limitation of Global SfM pipelines in general.
-
GlobalRotationEstimationType
ReconstructorEstimatorOptions::global_rotation_estimator_type¶ DEFAULT:
GlobalRotationEstimatorType::ROBUST_L1L2If the Global SfM pipeline is used, this parameter determines which type of global rotations solver is used. Options are
GlobalRotationEstimatorType::ROBUST_L1L2,GlobalRotationEstimatorType::NONLINEARandGlobalRotationEstimatorType::LINEAR. See below for more details on the various global rotations solvers.
-
GlobalPositionEstimationType
ReconstructorEstimatorOptions::global_position_estimator_type¶ DEFAULT:
GlobalPositionEstimatorType::NONLINEARIf the Global SfM pipeline is used, this parameter determines which type of global position solver is used. Options are
GlobalPositionEstimatorType::NONLINEAR,GlobalPositionEstimatorType::LINEAR_TRIPLETandGlobalPositionEstimatorType::LEAST_UNSQUARED_DEVIATION. See below for more details on the various global positions solvers.
-
int
ReconstructorEstimatorOptions::num_threads¶ DEFAULT:
1Number of threads to use during the various stages of reconstruction.
-
double
ReconstructorEstimatorOptions::max_reprojection_error_in_pixels¶ DEFAULT:
5.0Maximum reprojection error. This is used to determine inlier correspondences for absolute pose estimation. Additionally, this is the threshold used for filtering outliers after bundle adjustment.
-
int
ReconstructorEstimatorOptions::min_num_two_view_inliers¶ DEFAULT:
30Any edges in the view graph with fewer than this many inliers will be removed prior to any SfM estimation.
-
int
ReconstructorEstimatorOptions::num_retriangulation_iterations¶ DEFAULT:
1After computing a model and performing an initial BA, the reconstruction can be further improved (and even densified) if we attempt to retriangulate any tracks that are currently unestimated. For each retriangulation iteration we do the following:
- Remove features that are above max_reprojection_error_in_pixels.
- Triangulate all unestimated tracks.
- Perform full bundle adjustment.
-
double
ReconstructorEstimatorOptions::ransac_confidence¶ DEFAULT:
0.9999Confidence using during RANSAC. This determines the quality and termination speed of RANSAC.
-
int
ReconstructorEstimatorOptions::ransac_min_iterations¶ DEFAULT:
50Minimum number of iterations for RANSAC.
-
int
ReconstructorEstimatorOptions::ransac_max_iterations¶ DEFAULT:
1000Maximum number of iterations for RANSAC.
-
bool
ReconstructorEstimatorOptions::ransac_use_mle¶ DEFAULT:
trueUsing the MLE quality assessment (as opposed to simply an inlier count) can improve the quality of a RANSAC estimation with virtually no computational cost.
-
double
ReconstructorEstimatorOptions::rotation_filtering_max_difference_degrees¶ DEFAULT:
5.0After orientations are estimated, view pairs may be filtered/removed if the relative rotation of the view pair differs from the relative rotation formed by the global orientation estimations. That is, measure the angular distance between \(R_{i,j}\) and \(R_j * R_i^T\) and if it greater than
rotation_filtering_max_difference_degreesthan we remove that view pair from the graph. Adjust this threshold to control the threshold at which rotations are filtered.
-
bool
ReconstructorEstimatorOptions::refine_relative_translations_after_rotation_estimation¶ DEFAULT:
trueRefine the relative translations based on the epipolar error and known rotation estimations. This can improve the quality of the translation estimation.
-
bool
ReconstructorEstimatorOptions::refine_camera_positions_and_points_after_position_estimation¶ DEFAULT:
trueAfter estimating the camera position with Global SfM it is often advantageous to refine only the camera positions and points first before full bundle adjustment is run.
-
bool
ReconstructorEstimatorOptions::extract_maximal_rigid_subgraph¶ DEFAULT:
falseIf true, the maximal rigid component of the viewing graph will be extracted using the method of [KennedyIROS2012]. This means that only the cameras that are well-constrained for position estimation will be used. This method is somewhat slow, so enabling it will cause a performance hit in terms of efficiency.
-
bool
ReconstructorEstimatorOptions::filter_relative_translations_with_1dsfm¶ DEFAULT:
trueIf true, filter the pairwise translation estimates to remove potentially bad relative poses with the 1DSfM filter of [WilsonECCV2014]. Removing potential outliers can increase the performance of position estimation.
-
int
ReconstructorEstimatorOptions::translation_filtering_num_iterations¶ DEFAULT:
48The number of iterations that the 1DSfM filter runs for.
-
double
ReconstructorEstimatorOptions::translation_filtering_projection_tolerance¶ DEFAULT:
0.1A tolerance for the 1DSfM filter. Each relative translation is assigned a cost where the higher the cost, the more likely a relative translation is to be an outlier. Increasing this threshold makes the filtering more lenient, and decreasing it makes it more strict.
-
double
ReconstructorEstimatorOptions::rotation_estimation_robust_loss_scale¶ DEFAULT:
0.1Robust loss function width for nonlinear rotation estimation.
-
NonlinearPositionEstimator::Options
nonlinear_position_estimator_options¶ The position estimation options used for the nonlinear position estimation method. See below for more details.
-
LinearPositionEstimator::Options
linear_triplet_position_estimator_options¶ The position estimation options used for the linear position estimation method. See below for more details.
-
LeastUnsquaredDeviationPositionEstimator::Options
least_unsquared_deviation_position_estimator_options¶ The position estimation options used for the robust least unsquare deviation position estimation method. See below for more details.
-
double
ReconstructorEstimatorOptions::multiple_view_localization_ratio¶ DEFAULT:
0.8Used for incremental SfM only. If M is the maximum number of 3D points observed by any view, we want to localize all views that observe > M * multiple_view_localization_ratio 3D points. This allows for multiple well-conditioned views to be added to the reconstruction before needing bundle adjustment.
-
double
ReconstructionEstimatorOptions::absolute_pose_reprojection_error_threshold¶ DEFAULT:
4.0Used for incremental SfM only. When adding a new view to the current reconstruction, this is the reprojection error that determines whether a 2D-3D correspondence is an inlier during localization. This threshold is adaptive to the image resolution and is relative to an image with a width of 1024 pixels. This threshold scales up and down with images of varying resolutions appropriately.
-
int
ReconstructionEstimatorOptions::min_num_absolute_pose_inliers¶ DEFAULT:
30Used for incremental SfM only. Minimum number of inliers for absolute pose estimation to be considered successful.
-
double
ReconstructionEstimatorOptions::full_bundle_adjustment_growth_percent¶ DEFAULT:
5.0Used for incremental SfM only. Bundle adjustment of the entire reconstruction is triggered when the reconstruction has grown by more than this percent. That is, if we last ran BA when there were K views in the reconstruction and there are now N views, then G = (N - K) / K is the percent that the model has grown. We run bundle adjustment only if G is greater than this variable. This variable is indicated in percent so e.g., 5.0 = 5%.
-
int
ReconstructionEstimatorOptions::partial_bundle_adjustment_num_views¶ DEFAULT:
20Used for incremental SfM only. During incremental SfM we run “partial” bundle adjustment on the most recent views that have been added to the 3D reconstruction. This parameter controls how many views should be part of the partial BA.
-
double
ReconstructorEstimatorOptions::min_triangulation_angle_degrees¶ DEFAULT:
3.0In order to triangulate features accurately, there must be a sufficient baseline between the cameras relative to the depth of the point. Points with a very high depth and small baseline are very inaccurate. We require that at least one pair of cameras has a sufficient viewing angle to the estimated track in order to consider the estimation successful.
-
bool
ReconstructorEstimatorOptions::bundle_adjust_tracks¶ DEFAULT:
trueBundle adjust a track immediately after estimating it.
-
double
ReconstructorEstimatorOptions::triangulation_max_reprojection_error_in_pixels¶ DEFAULT:
10.0The reprojection error to use for determining a valid triangulation. If the reprojection error of any observation is greater than this value then we can consider the triangluation unsuccessful.
-
LossFunctionType
ReconstructionEstimatorOptions::bundle_adjustment_loss_function_type¶ DEFAULT:
LossFunctionType::TRIVIALA robust cost function may be used during bundle adjustment to increase robustness to noise and outliers during optimization.
-
double
ReconstructionEstimatorOptions::bundle_adjustment_robust_loss_width¶ DEFAULT:
10.0If a robust cost function is used, this is the value of the reprojection error at which robustness begins.
-
int
ReconstructorEstimatorOptions::min_cameras_for_iterative_solver¶ DEFAULT:
1000Use SPARSE_SCHUR for problems smaller than this size and ITERATIVE_SCHUR for problems larger than this size.
-
OptimizeIntrinsicsType
ReconstructorEstimatorOptions::intrinsics_to_optimize¶ DEFAULT: OptimizeIntrinsicsType::FOCAL_LENGTH | OptimizeIntrinsicsType::RADIAL_DISTORTION
The intrinsics parameters that are optimized during the bundle adjustment may be specified in a bitwise OR fashion. The various camera models will appropriately set the camera intrinsics parameters to be “free” or constant during optimization based on this parameters.
Incremental SfM Pipeline¶
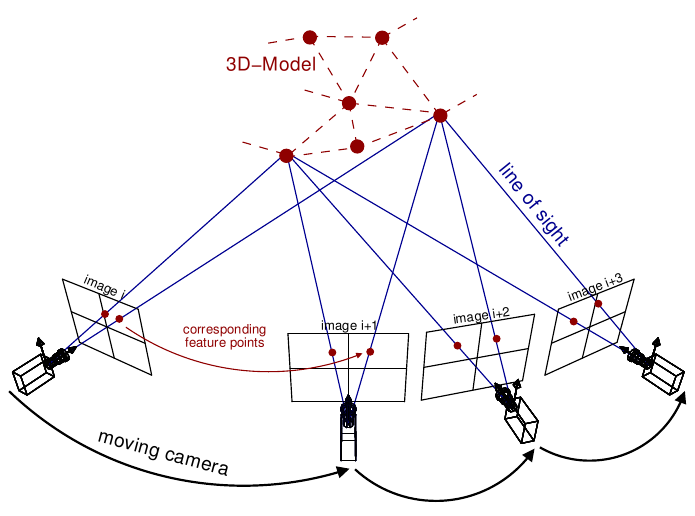
The incremental SfM pipeline follows very closely the pipelines of Bundler [PhotoTourism] and VisualSfM [VisualSfM]. The method begins by first estimating the 3D structure and camera poses of 2 cameras based on their relative pose. Then additional cameras are added on sequentially and new 3D structure is estimated as new parts of the scene are observed. Bundle adjustment is repeatedly performed as more cameras are added to ensure high quality reconstructions and to avoid drift.
- The incremental SfM pipeline is as follows:
- Choose an initial camera pair to reconstruct.
- Estimate 3D structure of the scene.
- Bundle adjustment on the 2-view reconstruction.
- Localize a new camera to the current 3D points. Choose the camera that observes the most 3D points currently in the scene.
- Estimate new 3D structure.
- Bundle adjustment if the model has grown by more than 5% since the last bundle adjustment.
- Repeat steps 4-6 until all cameras have been added.
Incremental SfM is generally considered to be more robust than global SfM methods; however, it requires many more instances of bundle adjustment (which is very costly) and so incremental SfM is not as efficient or scalable.
To use the Incremental SfM pipeline, simply set the
reconstruction_estimator_type to
ReconstructionEstimatorType::INCREMENTAL. There are many more options that
may be set to tune the incremental SfM pipeline that can be found in the
ReconstructionEstimatorOptions.
Global SfM Pipeline¶
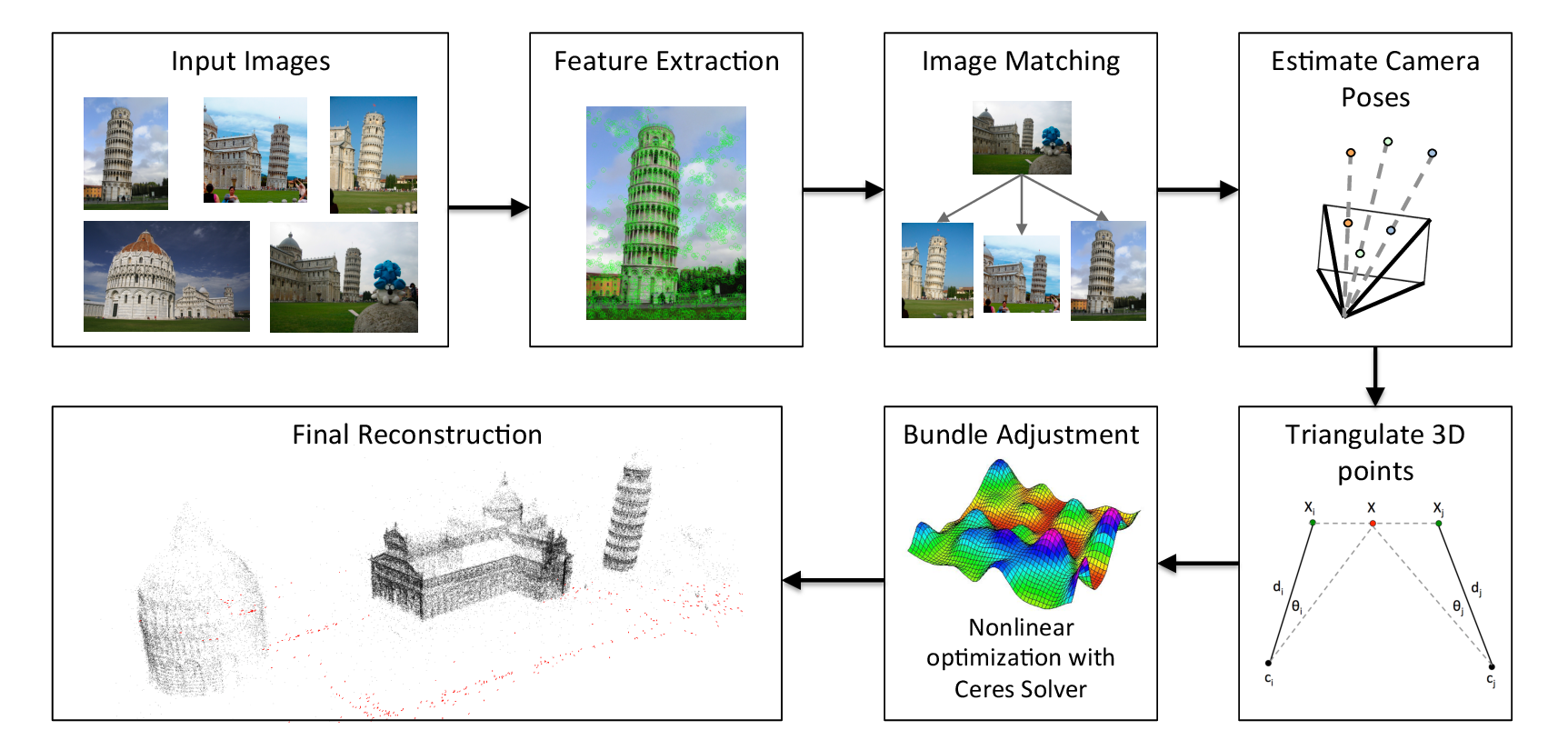
The global SfM pipelines in Theia follow a general procedure of filtering outliers and estimating camera poses or structure. Removing outliers can help increase performance dramatically for global SfM, though robust estimation methods are still required to obtain good results. The general pipeline is as follows:
- Create the initial view graph from 2-view matches and
TwoViewInfothat describes the relative pose between matched images.- Filter initial view graph and remove outlier 2-view matches.
- Calibrate internal parameters of all cameras (either from EXIF or another calibration method).
- Estimate global orientations of each camera with a
RotationEstimator- Filter the view graph: remove any TwoViewInfos where the relative rotation does not agree with the estimated global rotations.
- Refine the relative translation estimation to account for the estimated global rotations.
- Filter any bad
TwoViewInfobased on the relative translations.- Estimate the global positions of all cameras from the estimated rotations and
TwoViewInfousing aPositionEstimator- Estimate 3D points.
- Bundle adjust the reconstruction.
- (Optional) Attempt to estimate any remaining 3D points and bundle adjust again.
The steps above describe the general framework for global SfM, but there are many possible ways to, for instance, estimate rotations or estimate positions. Much work has been put into developing robust and efficient algorithms to solve these problems and, in theory, each algorithm should be easily inter-changeable.
Since Theia is built to be modular and extendible, we make it extremely easy to
implement and integrate new rotations solvers or positions solvers into the
global SfM framework. Theia implements a generic Global SfM interface
GlobalReconstructionEstimator that easily encapsulates all global SfM
pipelines. The GlobalReconstructionEstimator class makes calls to a
abstract RotationEstimator class and abstract
PositionEstimator class to estimate rotations and positions
respectively. Because these classes are abstract, this means we can easily
instantiate which type of solvers we want to use and are guaranteed to have the
same interface. This allows us to choose the rotation and position solvers at
run-time, making experiments with global SfM painless!
Estimating Global Rotations¶
-
class
RotationEstimator¶
Theia estimates the global rotations of cameras using an abstract interface
class RotationEstimator.
-
bool
RotationEstimator::EstimateRotations(const std::unordered_map<ViewIdPair, TwoViewInfo> &view_pairs, std::unordered_map<ViewId, Eigen::Vector3d> *global_orientations)¶ Using the relative poses as input, this function will estimate the global orientations for each camera. Generally speaking, this method will attempt to minimize the relative pose error:
(1)¶\[R_{i,j} = R_j * R_i^T`\]Note
This function does require an initial estimate of camera orientations. Initialization may be performed by walking a minimal spanning tree on the viewing graph, or another trivial method.
Implementing a new rotations solver is extremely easy. Simply derive from the
RotationEstimator class and implement the EstimateRotations method
and your new rotations solver will seamlessly plug into Theia’s global SfM
pipeline.
There are several types of rotation estimators that Theia implements natively:
- A Robust L1-L2
RobustRotationEstimator- A nonlinear
NonlinearRotationEstimator- A linear
LinearRotationEstimator
RobustRotationEstimator¶
-
class
RobustRotationEstimator¶ We recommend to use the
RobustRotationEstimatorof [ChatterjeeICCV13]. This rotation estimator utilizes L1 minimization to maintain efficiency to outliers. After several iterations of L1 minimization, an iteratively reweighted least squares approach is used to refine the solution.
-
int
RobustRotationEstimator::Options::max_num_l1_iterations¶ DEFAULT:
5Maximum number of L1 iterations to perform before performing the reweighted least squares minimization. Typically only a very small number of L1 iterations are needed.
-
int
RobustRotationEstimator::Options::max_num_irls_iterations¶ DEFAULT:
100Maximum number of reweighted least squares iterations to perform. These steps are much faster than the L2 iterations.
NonlinearRotationEstimator¶
-
class
NonlinearRotationEstimator¶ This class minimizes equation (1) using nonlinear optimization with the Ceres Solver. The angle-axis rotation parameterization is used so that rotations always remain on the SO(3) rotation manifold during the optimization.
-
NonlinearRotationEstimator::NonlinearRotationEstimator(const double robust_loss_width)¶ We utilize a Huber-like cost function during the optimization to remain robust to outliers. This robust_loss_width determines where the robustness kicks in.
LinearRotationEstimator¶
-
class
LinearRotationEstimator¶ This class minimizes (1) using a linear formulation. The constraints are set up in a linear system using rotation matrices and the optimal rotations are solved for using a linear least squares minimization described by [Martinec2007]. This minimization does not guarantee that the solution set will be valid rotation matrices (since it is finding any type of 3x3 matrices that minimize the linear system), so the solution is projected into the nearest SO(3) rotation matrix. As a result, this method is fast but may not always be the most accurate.
-
LinearRotationEstimator::LinearRotationEstimator(bool weight_terms_by_inliers)¶ If true, each term in the linear system will be weighted by the number of inliers such that two-view matches with many inliers are weighted higher in the linear system.
Estimating Global Positions¶
Positions of cameras may be estimated simultaneously after the rotations are known. Since positions encapsulate direction and scale information, the problem of estimating camera positions is fundamentally more difficult than estimating camera rotations. As such, there has been much work that has gone into estimating camera positions robustly and efficiently.
-
class
PositionEstimator¶
Similar to the RotationEstimator class, Theia utilizes an abstract
PositionEstimator class to perform position estimation. This class
defines the interface that all derived classes will use for estimating camera
positions. Like with the RotationEstimator, this abstract class helps
to keep the interface clean and allows for a simple way to change between
position estimation methods at runtime thanks to polymorphism.
-
bool
PositionEstimator::EstimatePositions(const std::unordered_map<ViewIdPair, TwoViewInfo> &view_pairs, const std::unordered_map<ViewId, Eigen::Vector3d> &orientation, std::unordered_map<ViewId, Eigen::Vector3d> *positions)¶ Input the view pairs containing relative poses between matched geometrically verified views, as well as the global (absolute) orientations of the camera that were previously estimated. Camera positions are estimated from this information, with the specific strategies and implementation determined by the derived classes.
Returns true if the position estimation was a success, false if there was a failure. If false is returned, the contents of positions are undefined.
Generally, the position estimation methods attempt to minimize the deviation from the relative translations:
(2)¶\[R_i * (c_j - c_i) = \alpha_{i,j} * t_{i,j}\]This equation is used to determine the global camera positions, where \(\alpha_{i,j} = ||c_j - c_i||^2\). This ensures that we optimize for positions that agree with the relative positions computed in two-view estimation.
NonlinearPositionEstimator¶
-
class
NonlinearPositionEstimator¶
This class attempts to minimize the position constraint of (2) with a nonlinear solver that minimizes the chordal distance [WilsonECCV2014]. A robust cost function is utilized to remain robust to outliers.
-
NonlinearPositionEstimator(const NonlinearPositionEstimator::Options &options, const Reconstruction &reconstruction)¶ The constructor takes the options for the nonlinear position estimator, as well as const references to the reconstruction (which contains camera and track information) and the two view geometry information that will be use to recover the positions.
-
int
NonlinearPositionEstimator::Options::num_threads¶ DEFAULT:
1Number of threads to use with Ceres for nonlinear optimization.
-
int
NonlinearPositionEstimator::Options::max_num_iterations¶ DEFAULT:
400The maximum number of iterations for the minimization.
-
double
NonlinearPositionEstimator::Options::robust_loss_width¶ DEFAULT:
0.1The width of the robust Huber loss function used.
-
int
NonlinearPositionEstimator::Options::min_num_points_per_view¶ DEFAULT:
0The number of 3D point-to-camera constraints to use for position recovery. Using points-to-camera constraints can sometimes improve robustness to collinear scenes. Points are taken from tracks in the reconstruction such that the minimum number of points is used such that each view has at least
min_num_points_per_viewpoint-to-camera constraints.
-
double
NonlinearPositionEstimator::Options::point_to_camera_weight¶ DEFAULT:
0.5Each point-to-camera constraint (if any) is weighted by
point_to_camera_weightcompared to the camera-to-camera weights.
LinearPositionEstimator¶
-
class
LinearPositionEstimator¶
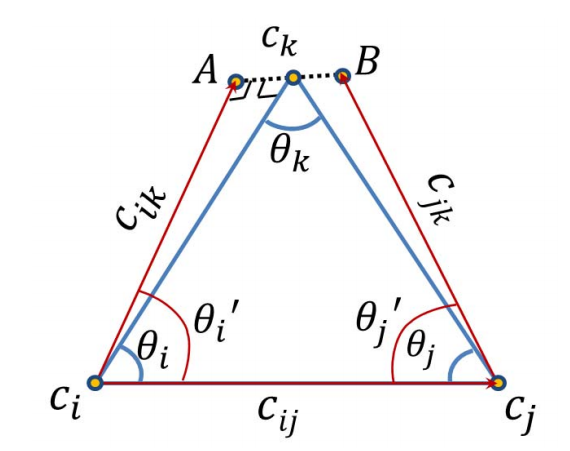
For the linear position estimator of [JiangICCV], we utilize an approximate geometric error to determine the position locations within a triplet as shown above. The cost function we minimize is:
\[f(i, j, k) = c_k - \dfrac{1}{2} (c_i + ||c_k - c_i|| c_{ik}) + c_j + ||c_k - c_j|| c_{jk})\]
This can be formed as a linear constraint in the unknown camera positions \(c_i\). The solution that minimizes this cost lies in the null-space of the resultant linear system. Instead of extracting the entire null-space as [JiangICCV] does, we instead hold one camera constant at the origin and use the Inverse-Iteration Power Method to efficiently determine the null vector that best solves our minimization. This results in a dramatic speedup without sacrificing efficiency.
-
LinearPositionEstimator::LinearPositionEstimator(const LinearPositionEstimator::Options &options, const Reconstruction &reconstruction)¶
-
int
LinearPositionEstimator::Options::num_threads¶ DEFAULT:
1The number of threads to use to solve for camera positions
-
int
LinearPositionEstimator::Options::max_power_iterations¶ DEFAULT:
1000Maximum number of power iterations to perform while solving for camera positions.
-
double
LinearPositionEstimator::Options::eigensolver_threshold¶ DEFAULT:
1e-8This number determines the convergence of the power iteration method. The lower the threshold the longer it will take to converge.
LeastUnsquareDeviationPositionEstimator¶
-
class
LeastUnsquaredDeviationPositionEstimator¶
Estimates the camera position of views given pairwise relative poses and the absolute orientations of cameras. Positions are estimated using a least unsquared deviations solver – essentially an L1 solver that is wrapped in an Iteratively Reweighted Least Squares (IRLS) formulation. This method was proposed in [OzyesilCVPR2015].
-
LeastUnsquaredDeviationPositionEstimator(const LeastUnsquaredDeviationPositionEstimator::Options &options, const Reconstruction &reconstruction)¶ The constructor takes the options for the nonlinear position estimator, as well as const references to the reconstruction (which contains camera and track information) and the two view geometry information that will be use to recover the positions.
-
int
LeastUnsquaredDeviationPositionEstimator::Options::max_num_iterations¶ DEFAULT:
400The maximum number of iterations for the minimization.
-
int
LeastUnsquaredDeviationPositionEstimator::Options::max_num_reweighted_iterations¶ DEFAULT:
10The maximum number of reweighted iterations in the IRLS scheme.
-
int
LeastUnsquaredDeviationPositionEstimator::Options::convergence_criterion¶ DEFAULT:
1e-4A measurement for determining the convergence of the IRLS scheme. Increasing the value will make the IRLS scheme converge earlier.
Triangulation¶
Triangulation in structure from motion calculates the 3D position of an image coordinate that has been tracked through two or more images. All cameras with an estimated camera pose are used to estimate the 3D point of a track.
- class
EstimateTrackOptions¶
- bool
EstimateTrackOptions::bundle_adjustment¶DEFAULT:
trueBundle adjust the track (holding all camera parameters constant) after initial estimation. This is highly recommended in order to obtain good 3D point estimations.
- double
EstimateTrackOptions::max_acceptable_reprojection_error_pixels¶DEFAULT:
5.0Track estimation is only considered successful if the reprojection error for all observations is less than this value.
- double
EstimateTrackOptions::min_triangulation_angle_degrees¶DEFAULT:
3.0In order to triangulate features accurately, there must be a sufficient baseline between the cameras relative to the depth of the point. Points with a very high depth and small baseline are very inaccurate. We require that at least one pair of cameras has a sufficient viewing angle to the estimated track in order to consider the estimation successful.
- bool
EstimateAllTracks(const EstimateTrackOptions &options, const int num_threads, Reconstruction *reconstruction)¶Performs (potentially multithreaded) track estimation. Track estimation is embarrassingly parallel so multithreading is recommended.
- bool
Triangulate(const Matrix3x4d &pose1, const Matrix3x4d &pose2, const Eigen::Vector2d &point1, const Eigen::Vector2d &point2, Eigen::Vector4d *triangulated_point)¶2-view triangulation using the method described in [Lindstrom]. This method is optimal in an L2 sense such that the reprojection errors are minimized while enforcing the epipolar constraint between the two cameras. Additionally, it basically the same speed as the
TriangulateDLT()method.The poses are the (potentially calibrated) poses of the two cameras, and the points are the 2D image points of the matched features that will be used to triangulate the 3D point. On successful triangulation,
trueis returned. The homogeneous 3d point is output so that it may be known if the point is at infinity.
- bool
TriangulateDLT(const Matrix3x4d &pose1, const Matrix3x4d &pose2, const Eigen::Vector2d &point1, const Eigen::Vector2d &point2, Eigen::Vector4d *triangulated_point)¶The DLT triangulation method of [HartleyZisserman].
- bool
TriangulateMidpoint(const Eigen::Vector3d &origin1, const Eigen::Vector3d &ray_direction1, const Eigen::Vector3d &origin2, const Eigen::Vector3d &ray_direction2, Eigen::Vector4d *triangulated_point)¶Perform triangulation by determining the closest point between the two rays. In this case, the ray origins are the camera positions and the directions are the (unit-norm) ray directions of the features in 3D space. This method is known to be suboptimal at minimizing the reprojection error, but is approximately 10x faster than the other 2-view triangulation methods.
- bool
TriangulateNViewSVD(const std::vector<Matrix3x4d> &poses, const std::vector<Eigen::Vector2d> &points, Eigen::Vector3d *triangulated_point)¶
- bool
TriangulateNView(const std::vector<Matrix3x4d> &poses, const std::vector<Eigen::Vector2d> &points, Eigen::Vector3d *triangulated_point)¶We provide two N-view triangluation methods that minimizes an algebraic approximation of the geometric error. The first is the classic SVD method presented in [HartleyZisserman]. The second is a custom algebraic minimization. Note that we can derive an algebraic constraint where we note that the unit ray of an image observation can be stretched by depth \(\alpha\) to meet the world point \(X\) for each of the \(n\) observations:
\[\alpha_i \bar{x_i} = P_i X,\]for images \(i=1,\ldots,n\). This equation can be effectively rewritten as:
\[\alpha_i = \bar{x_i}^\top P_i X,\]which can be substituted into our original constraint such that:
\[\bar{x_i} \bar{x_i}^\top P_i X = P_i X\]\[0 = (P_i - \bar{x_i} \bar{x_i}^\top P_i) X\]We can then stack this constraint for each observation, leading to the linear least squares problem:
\[\begin{split}\begin{bmatrix} (P_1 - \bar{x_1} \bar{x_1}^\top P_1) \\ \vdots \\ (P_n - \bar{x_n} \bar{x_n}^\top P_n) \end{bmatrix} X = \textbf{0}\end{split}\]This system of equations is of the form \(AX=0\) which can be solved by extracting the right nullspace of \(A\). The right nullspace of \(A\) can be extracted efficiently by noting that it is equivalent to the nullspace of \(A^\top A\), which is a 4x4 matrix.
Bundle Adjustment¶
We perform bundle adjustment using Ceres Solver for nonlinear optimization. Given a
Reconstruction, we optimize over all cameras and 3D points to minimize
the reprojection error.
-
class
BundleAdjustmentOptions¶
-
LossFunctionType
BundleAdjustmentOptions::loss_function_type¶ DEFAULT:
TRIVIALA robust cost function may be used during bundle adjustment to increase robustness to noise and outliers during optimization.
-
double
BundleAdjustmentOptions::robust_loss_width¶ DEFAULT:
10.0If a robust cost function is used, this is the value of the reprojection error at which robustness begins.
-
ceres::LinearSolverType
BundleAdjustmentOptions::linear_solver_type¶ DEFAULT:
ceres::SPARSE_SCHURceres::DENSE_SCHUR is recommended for problems with fewer than 100 cameras, ceres::SPARSE_SCHUR for up to 1000 cameras, and ceres::ITERATIVE_SCHUR for larger problems.
-
ceres::PreconditionerType
BundleAdjustmentOptions::preconditioner_type¶ DEFAULT:
ceres::SCHUR_JACOBIIf ceres::ITERATIVE_SCHUR is used, then this preconditioner will be used.
-
ceres::VisibilityClusteringType
BundleAdjustmentOptions::visibility_clustering_type¶ DEFAULT:
ceres::SINGLE_LINKAGE
-
bool
BundleAdjustmentOptions::verbose¶ DEFAULT:
falseSet to true for verbose logging.
-
bool
BundleAdjustmentOptions::constant_camera_orientation¶ DEFAULT:
falseIf true, hold the camera orientations constant during bundle adjustment.
-
bool
BundleAdjustmentOptions::constant_camera_position¶ DEFAULT:
falseIf true, hold the camera positions constant during bundle adjustment.
-
OptimizeIntrinsicsType
BundleAdjustmentOptions::intrinsics_to_optimize¶ DEFAULT: OptimizeIntrinsicsType::FOCAL_LENGTH | OptimizeIntrinsicsType::RADIAL_DISTORTION
Set to the bitwise OR of the parameters you wish to optimize during bundle adjustment.
-
int
BundleAdjustmentOptions::num_threads¶ DEFAULT:
1The number of threads used by Ceres for optimization. More threads means faster solving time.
-
int
BundleAdjustmentOptions::max_num_iterations¶ DEFAULT:
500Maximum number of iterations for Ceres to perform before exiting.
-
double
BundleAdjustmentOptions::max_solver_time_in_seconds¶ DEFAULT:
3600.0Maximum solver time is set to 1 hour.
-
bool
BundleAdjustmentOptions::use_inner_iterations¶ DEFAULT:
trueInner iterations can help improve the quality of the optimization.
-
double
BundleAdjustmentOptions::function_tolerance¶ DEFAULT:
1e-6Ceres parameter for determining convergence.
-
double
BundleAdjustmentOptions::gradient_tolerance¶ DEFAULT:
1e-10Ceres parameter for determining convergence.
-
double
BundleAdjustmentOptions::parameter_tolerance¶ DEFAULT:
1e-8Ceres parameter for determining convergence.
-
double
BundleAdjustmentOptions::max_trust_region_radius¶ DEFAULT:
1e12Maximum size that the trust region radius can grow during optimization. By default, we use a value lower than the Ceres default (1e16) to improve solution quality.
-
BundleAdjustmentSummary
BundleAdjustReconstruction(const BundleAdjustmentOptions &options, Reconstruction *reconstruction)¶ Performs full bundle adjustment on a reconstruction to optimize the camera reprojection error. The BundleAdjustmentSummary returned contains information about the success of the optimization, the initial and final costs, and the time required for various steps of bundle adjustment.
Similarity Transformation¶
- void
AlignPointCloudsICP(const int num_points, const double left[], const double right[], double rotation[], double translation[])¶We implement ICP for point clouds. We use Besl-McKay registration to align point clouds. We use SVD decomposition to find the rotation, as this is much more likely to find the global minimum as compared to traditional ICP, which is only guaranteed to find a local minimum. Our goal is to find the transformation from the left to the right coordinate system. We assume that the left and right reconstructions have the same number of points, and that the points are aligned by correspondence (i.e. left[i] corresponds to right[i]).
- void
AlignPointCloudsUmeyama(const int num_points, const double left[], const double right[], double rotation[], double translation[], double *scale)¶This function estimates the 3D similarity transformation using the least squares method of [Umeyama]. The returned rotation, translation, and scale align the left points to the right such that \(Right = s * R * Left + t\).
- void
GdlsSimilarityTransform(const std::vector<Eigen::Vector3d> &ray_origin, const std::vector<Eigen::Vector3d> &ray_direction, const std::vector<Eigen::Vector3d> &world_point, std::vector<Eigen::Quaterniond> *solution_rotation, std::vector<Eigen::Vector3d> *solution_translation, std::vector<double> *solution_scale)¶Computes the solution to the generalized pose and scale problem based on the paper “gDLS: A Scalable Solution to the Generalized Pose and Scale Problem” by Sweeney et. al. [SweeneyGDLS]. Given image rays from one coordinate system that correspond to 3D points in another coordinate system, this function computes the rotation, translation, and scale that will align the rays with the 3D points. This is used for applications such as loop closure in SLAM and SfM. This method is extremely scalable and highly accurate because the cost function that is minimized is independent of the number of points. Theoretically, up to 27 solutions may be returned, but in practice only 4 real solutions arise and in almost all cases where n >= 6 there is only one solution which places the observed points in front of the camera. The rotation, translation, and scale are defined such that: \(sp_i + \alpha_i d_i = RX_i + t\) where the observed image ray has an origin at \(p_i\) in the unit direction \(d_i\) corresponding to 3D point \(X_i\).
ray_origin: the origin (i.e., camera center) of the image ray used in the 2D-3D correspondence.
ray_direction: Normalized image rays corresponding to reconstruction points. Must contain at least 4 points.
world_point: 3D location of features. Must correspond to the image_ray of the same index. Must contain the same number of points as image_ray, and at least 4.
solution_rotation: the rotation quaternion of the candidate solutions
solution_translation: the translation of the candidate solutions
solution_scale: the scale of the candidate solutions
- void
SimTransformPartialRotation(const Eigen::Vector3d &rotation_axis, const Eigen::Vector3d image_one_ray_directions[5], const Eigen::Vector3d image_one_ray_origins[5], const Eigen::Vector3d image_two_ray_directions[5], const Eigen::Vector3d image_two_ray_origins[5], std::vector<Eigen::Quaterniond> *soln_rotations, std::vector<Eigen::Vector3d> *soln_translations, std::vector<double> *soln_scales)¶Solves for the similarity transformation that will transform rays in image two such that the intersect with rays in image one such that:
\[s * R * X' + t = X\]where s, R, t are the scale, rotation, and translation returned, X’ is a point in coordinate system 2 and X is the point transformed back to coordinate system 1. Up to 8 solutions will be returned.
Please cite the paper “Computing Similarity Transformations from Only Image Correspondences” by C. Sweeney et al (CVPR 2015) [SweeneyCVPR2015] when using this algorithm.